Path Matters: What We Built, What We Found, and What Comes Next
Published:
After six months of work, the Path Matters project is submitted. This post is a summary of what we built, the results we got, and what I personally learned from it. The full report is available through TU Berlin.
The project ran as an automation engineering course at TU Berlin (WiSe 25/26), supervised by Adam Altenbuchner at the Institut für Werkzeugmaschinen und Fabrikbetrieb. Five engineers: Artem Balatsiuk, Aziz Louati, Haroun Lallouche, Taha Mohammed (me), and Ziad Abouhalawa. The question we were trying to answer was simple to state and genuinely hard to answer: does the choice and sequence of camera viewpoints significantly affect the quality of 3D reconstruction from a robotic scanner?
What we built
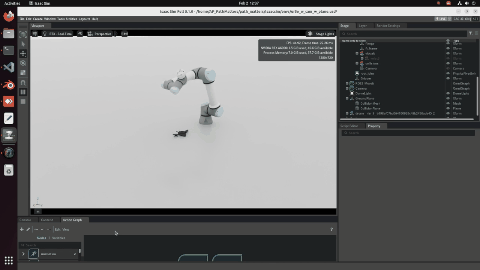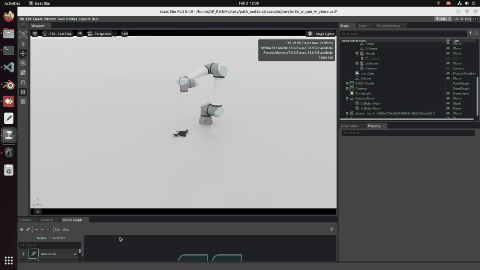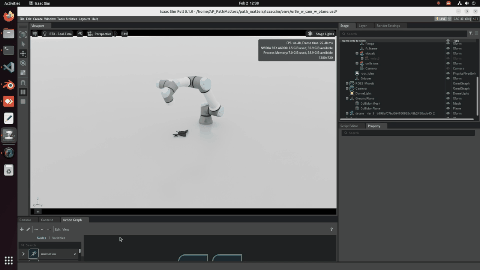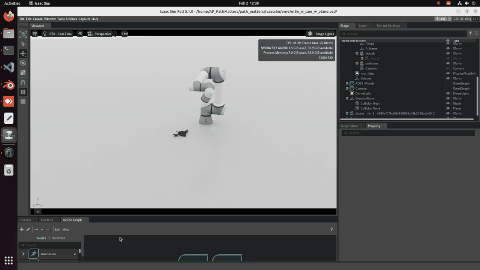
The system is a modular pipeline connecting a UR5e robot arm in NVIDIA Isaac Sim, controlled through ROS2 Humble and MoveIt2, to three reconstruction models (VGGT, Fast3R, SAM3D), and an evaluation pipeline using ICP and BUFFER-X to measure alignment quality against ground-truth meshes. My responsibility was trajectory planning — designing the motion strategies, implementing the ROS2 control pipeline, and running the scanning experiments.
The pipeline has four independent modules that communicate through a shared directory structure: trajectory (viewpoint generation and execution), data (image export and point cloud management), reconstruction (wrapping all three models behind a common interface), and evaluation (ICP registration and metric computation). This design made it possible to swap any component and compare results systematically.
Reconstruction: VGGT wins clearly
We evaluated VGGT, Fast3R, and SAM3D on 28 objects drawn from Isaac Sim synthetic data, Google Scanned Objects, T-LESS and Linemod benchmarks, and real-world hand-held captures. Each method received the same set of 12 images from a fixed hemispheric trajectory, and we measured ICP Fitness and RMSE after registration against the ground-truth mesh.
VGGT: Fitness 0.93, RMSE 0.002 m. Fast3R: Fitness 0.89, RMSE 0.010 m. SAM3D: Fitness 0.91, RMSE 0.008 m. All three finish inference in under 10 seconds on our RTX A6000. VGGT wins on both metrics and became the primary reconstruction backbone for all subsequent experiments.
One practical complication: VGGT and Fast3R produce reconstructions in an arbitrary scene-relative scale with no absolute metric information. Before registration, you need to estimate the scale factor. We used a median consensus approach combining three estimators — bounding box diagonal ratio, PCA axis length ratios, and convex hull volume ratio. In extreme mismatch cases, this improved ICP Fitness from 0.0 to 1.0. Without scale correction, the alignment metrics are meaningless.
Registration: ICP outperforms BUFFER-X here, but context matters
For our evaluation setting — preprocessed point clouds with reasonable initial alignment — ICP with FPFH initialisation outperformed BUFFER-X on all metrics: Fitness 0.87 versus 0.81, RMSE 0.0041 m versus 0.0063 m, recall above 0.8 threshold at 78.6% versus 67.9%. BUFFER-X is faster (1.8 s versus 3.2 s) and does not require a coarse initial alignment, which makes it useful when RANSAC fails. The two methods are complementary rather than competing.
Trajectory: camera orientation is the biggest lever
I ran five scanning patterns (Lawnmower, Zigzag, Hemisphere, Spiral, Random) under two camera orientation strategies. Approach 1: camera always points straight down. Approach 2: camera dynamically points toward the detected object centre at every waypoint.
Approach 1 mean ICP Fitness across all patterns: 0.68. Approach 2 mean: 0.79. The improvement was consistent across every pattern without changing the number of viewpoints or the trajectory geometry. The best single result was Hemisphere with Approach 2: Fitness 0.86, RMSE 0.015 m.
This was the clearest finding of the trajectory experiments: camera orientation matters more than trajectory pattern at this scale. Which pattern you use — lawnmower, hemisphere, spiral — has a secondary effect compared to whether the camera is actually looking at the object from each position. The implementation cost of dynamic object-pointing orientation is modest (slightly more complex IK solutions, around 5% IK failure rate versus 0% for fixed downward, and 0.5 s longer stabilisation pause), and the quality gain is substantial.
Reinforcement learning: proximity shaping solves the sparse reward problem
The RL component uses Isaac Lab with 16 parallel UR5e environments, PPO, and an 86-dimensional state space including joint positions, camera pose, coverage percentage, and an 8x8 downsampled voxel coverage map. The agent selects continuous joint position deltas; images are captured automatically every 20 steps.
First experiment (exp_06): coverage rewards only, no signal toward the scanning volume. Task success rate: 0.4%. The robot occasionally stumbled into good positions by chance but could not reproduce the behaviour.
Second experiment (exp_07): added three proximity shaping rewards providing a continuous gradient toward the workspace — a proximity gradient toward the volume centre, a binary reward for being inside the workspace bounds, and a dot-product reward for facing the volume. Task success rate: 45.2%. Coverage: 75% or more per episode. Versus random exploration: 3.6x higher coverage, 75%+ versus 20.6%.
The practical lesson is that proximity shaping is not a nice-to-have: it is necessary for this environment. Without a gradient guiding the robot toward the scanning volume, the coverage rewards never activate and learning stalls. The agent needs to learn to get close before it can learn to scan.
There is a known limitation: the RL agent maximises geometric voxel coverage (frustum-based), not actual reconstruction quality. Coverage and ICP Fitness are correlated but not identical. The obvious next step — and the open research question the project leaves behind — is to replace the geometric coverage metric with direct ICP Fitness or VGGT confidence as the reward signal.
What I would do differently
The preprocessing pipeline (RANSAC plane removal, DBSCAN clustering) failed on roughly 15% of objects — either removing part of the object or not finding the table plane. These failures propagated into degraded scale estimation and registration. More robust preprocessing, or replacing it with a learned segmentation approach like YOLO-based semantic crop, would have improved the tail of the distribution.
The RL training stability was also not fully resolved. The exp_07 task success rate peaks near 100% around iteration 1500 before settling at 40–45%. For deployment, you would need to select the peak checkpoint rather than the final one. Entropy coefficient scheduling and learning rate decay would likely improve convergence.
What comes next
For me personally, this project confirmed that I want to keep working on robotic perception and learning-based control, specifically the problems around sim-to-real transfer and direct optimisation of reconstruction quality through robot behaviour. The trajectory planning work connects directly to the reward signal design question in the RL component, and both connect to the calibration work I did at Fraunhofer IPK. I am looking for a PhD position where I can develop these threads further.
The full report, code, and results are available on request. If you are working on related problems and want to discuss, feel free to reach out.